什麼是 Garbage Collection
在大學時 Algorithm, OS, 和 Data Structure 等課程都是使用 C 或 C++ 來當作課程教材的語言。而 C 與 C++ 語言可以擁有很大的掌控權力在 Memory 上,但是一處理不好就容易造成 Memory Leak。讓我印象最深刻的是 Operating System 課程,使用 OS161 來當作做作業的練習, 而最後一個作業就是實作 Memory Management。大家那時候最害怕遇到的錯誤訊息就是 “I can’t handle this… I think I’ll just die now…",然後就要開始艱辛的 Debug 路程。
之後當我接觸 Java 以後,我就回不去了 C 和 C++ 的世界了。因為 Java 已經有一套非常完善的機制幫我們管理記憶體,那就是 Garbage Collection。 Garbage Collection 是一個演算法,會自動將不需要在使用的內存給釋放出來,而我們就不用在管理複雜的記憶體了萬歲~
Garbage Collection 演算法
Reference Counting
這是最簡單易懂的演算法,每個物件都有個記地址去紀錄目前被多少引用,當引用數量等於零時,就代表這個物件可以被清除掉。
Reference Counting演算法的問題是 Cycle Reference。例如A reference B 和 B reference A,這樣 A 和 B 的引用的數量永遠不可能為零,也代表永遠不會被清除。
Mark & Sweep
Mark & Sweep 演算法一共用兩個階段,如同英文 Mark 和 Sweep 分別代表不同的階段 階段1. Mark: 就是透過根引用開始一一走過一遍目前的記憶體,將所有有被引用的物件地址標記為正在使用。 階段2. Sweep: 在走過一次將地址將所有沒有被標記為還正在使用的記憶體清除。
Mark & Sweep 演算法的問題是記憶碎片(fragmentation),由於被清除的記憶是隨機的,造成剩下還正在使用的記憶地址是非連續性的。
Copying
Copying 演算法是將記憶體切成兩個區塊(Region),一次只會有一個區塊在使用,這邊分別使用 “激活區塊” 和 “未激活區塊” 來表示。當演算法執行時,會將所有在 “激活區塊” 中還需要使用的物件複製到 “未激活區塊中”。在複製的過程中,會將地址重新整理,解決了 Mark & Sweep 演算法中的 Fragmentation 的問題。複製完後 “未激活區塊” 就會變成新的 “激活區塊”,而 “激活區塊” 會變成 “未激活區塊” 這樣一直循環。
Copying 演算法的問題是
- 由於需要兩個區塊,所以使用的記憶體也是兩倍。
- 如果每次執行時,需要清理的記憶體很少,那就代表每次需要複製到 “未激活區塊” 的很多,效能也會很差
Mark-Compact
Mark-Compact 演算法是基於 Mark & Sweep 演算法的優化,多增加一個 Compact 階段,將還需要使用的記憶重新整理,解決了記憶碎片,也不像 Copying 演算法依樣需要使用兩倍的記憶體
Java Garbage Collection
Generation Collector
Generation 演算法的核心理論在於大部分的物件很快就是被清掉,如果沒被清掉,就不需要這麼頻繁的一直重複確認是否存在。Generation 演算法會將記憶體分為 Young & Old Generation。Young Generation 用於存放所有新物件,在幾次 GC 後還在 Young Generation 未清除的物件,將被升級到 Old Generation。
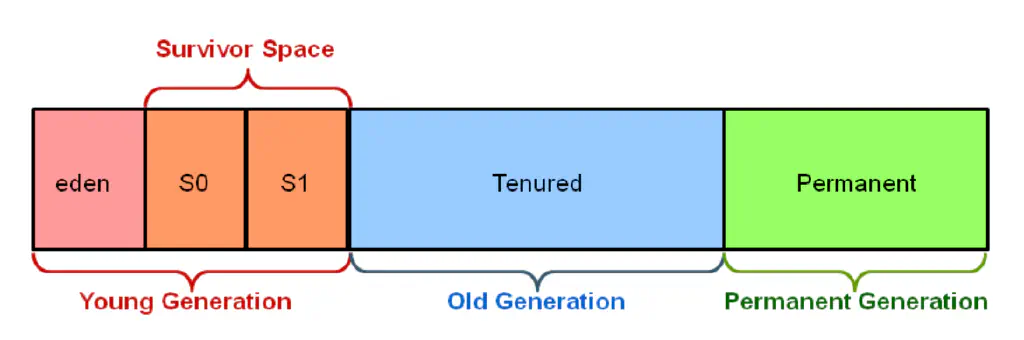
如上圖 Java 將記憶體資料結構分為
- Young Generation
- 有兩個
survivor空間,也就是圖上的 S0 & S1- 這邊使用 Copying 演算法,將物件在 S0 與 S1 之間複製。
- 複製到一定次數會被升級到 Olde Generation
- Eden Space: 這邊用於存新的物件,在第一次 GC 時,沒有被清除就會移到 S0 or S1
- 有兩個
- Old Generation
- 這邊使用 Mark-Compact 演算法。
- Permanent Generation
- 這邊用於存取 JVM 長期需要使用的資料,例如 Class, Method 等等。這裡的資料不會被 GC 掉
Generation 演算法中有個特別的資料結構叫做 Card Table,想像如果現在要 GC Young Generation,而 Young Generation 萬一有 Old Generation 裡面的記憶體來引用那要怎麼辦?這樣是否每次在 GC Young Generation 時都要去 Full Scan Old Generation 是否有任何索引?但這樣效能就會很差,而 Card Table 就是用於處理這樣的情況。在 Card Table 中會紀錄現在 Old Generation 的地址是否有引用 Young Generation 的,這樣在 Young Generation GC 時可以透過 Card Table 來增加效能。
Region

Java9 現在預設的 Garbage Collection G1 是使用 Region 演算法。如上圖,Region 演算法還是有 Generation 的概念,但跟 Generation 演算法不同的地方是,它將記憶體切成多個不同大小(1 MB 到 32 MB 不等)的 Region。由於更多的區塊,所以可以並發GC,而且也因為每個 Region 更小,所以 GC 的數度更快。
Java 取得 Garbage Collection 資訊
Java 有特別的 Garbage Collection 接口 GarbageCollectorMXBean,以下是範例
1package com.javacore.gc;
2
3import java.lang.management.GarbageCollectorMXBean;
4import java.lang.management.ManagementFactory;
5import java.util.List;
6
7public class MxBean {
8
9 public static void main(String[] args) {
10 List<GarbageCollectorMXBean> beanList = ManagementFactory.getGarbageCollectorMXBeans();
11 for (GarbageCollectorMXBean bean: beanList) {
12 System.out.println("Name: " + bean.getName());
13 System.out.println("Number of Collection Count: " + bean.getCollectionCount());
14 System.out.println("Collection Time " + bean.getCollectionTime() + "ms");
15 System.out.println("Pool Name " + bean.getName());
16
17 for(String pool : bean.getMemoryPoolNames()) {
18 System.out.println(pool);
19 }
20 System.out.println();
21 }
22 }
23}
- getCollectionCount(): 以執行次數
- getCollectionTime(): 預計以執行 Total 時間,單位為毫秒
以下是 Open JDK11 預設 G1 執行結果
1Name: G1 Young Generation
2Number of Collection Count: 0
3Collection Time 0
4Pool Name G1 Young Generation
5G1 Eden Space
6G1 Survivor Space
7G1 Old Gen
8
9Name: G1 Old Generation
10Number of Collection Count: 0
11Collection Time 0
12Pool Name G1 Old Generation
13G1 Eden Space
14G1 Survivor Space
15G1 Old Gen

評論